前一天將檔案上傳上向量資料庫後,我們需要有一個聊天的頁面,為此我們須需要額外的前端頁面
至於設計嘛,先能用就好,總之先做一個像聊天室的介面吧
./chat_page.py
import gradio as gr
from utils import File, Chat, qdrant_client
from dotenv import load_dotenv
load_dotenv(dotenv_path="./.env", override=True)
with gr.Blocks() as demo:
with gr.Row():
with gr.Column():
chatbot = gr.Chatbot(layout="bubble", show_label=False)
textbox = gr.Textbox(placeholder="請在這邊輸入文字...")
submit_btn = gr.Button(value="送出")
submit_btn.click(
Chat.send_query,
inputs=[textbox, chatbot],
outputs=[textbox, chatbot]
)
if __name__ == "__main__":
demo.launch(
server_port=7860,
server_name="0.0.0.0"
)
./utils.py
utils.py 可以共用,所以在底下多新增一個類別即可
mport os
import gradio as gr
from qdrant_client import QdrantClient
from langchain_community.chat_models import ChatOllama
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
qdrant_client = QdrantClient(url=os.getenv("OLLAMA_SERVER_URL"))
qdrant_client.set_model("intfloat/multilingual-e5-large", cache_dir="./.cache")
lass File:
def upload_file(file_paths: list):
yield "上傳中"
try:
for file_path in file_paths:
reader = PyPDF2.PdfReader(open(file_path, 'rb'))
for index in range(len(reader.pages)):
qdrant_client.add(
collection_name="iron",
documents=[reader.pages[index].extract_text()],
metadata=[{"filename": os.path.basename(file_path)}]
)
except:
yield "上傳失敗"
yield "上傳成功"
class Chat:
def send_query(search_content: str, history: list):
history.append([search_content, ""])
yield "", history
# 搜尋相似向量,這邊限制回傳一筆結果
result = qdrant_client.query(
collection_name="iron",
query_text=search_content,
limit=1
)
# 遍歷所有搜尋結果,並將檔案名稱、頁碼、段落資訊組合成一個字串
content = "\n\n--------------------------\n\n".join(point.metadata["document"] for point in result)
llm = ChatOllama(
model="gemma2",
base_url=os.getenv("OLLAMA_SERVER_URL")
)
# 初始化提詞
prompt_template = f"""你必須根據參考資料中的不同段落的資訊來回答使用者問題,回覆必須用繁體中文。
# 參考資料
{{content}}
# 使用者問題
Question: {{question}}"""
# 用 stream 的方法與 Ollama 互動並且使用 yield 來將結果回傳給前端
response = chain = (
{"content": lambda x: content ,"question": RunnablePassthrough()}
| ChatPromptTemplate.from_template(prompt_template)
| llm
| StrOutputParser()
).stream(search_content)
for chunk in response:
history[-1][1] += chunk
yield "", history
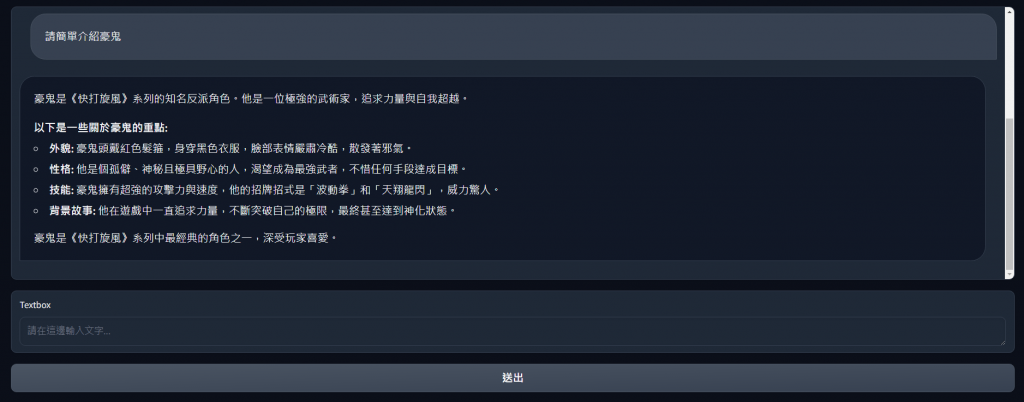
而實際運行的效果如下面所示,利用上傳的文件資訊,結合提示詞的幫助,簡單的從向量資料庫中搜尋結果並且根據使用者的問題去整理出結果,以下是我詢問「請簡單介紹豪鬼」的問題給予的回覆
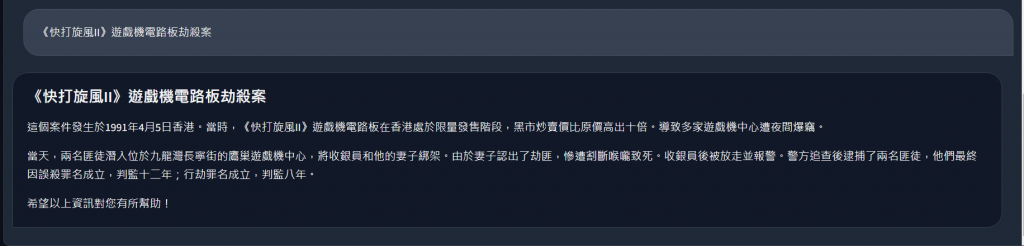
當然,一份小文件實在說不上甚麼相似搜尋,所以我們再上傳一份檔案,一樣是跟快打旋風有關的快打旋風-角色的資訊
這時我們再問一個新的問題,可以看到我們的相似搜尋也可以正確的搜尋出結果


 iThome鐵人賽
iThome鐵人賽